
Update on the Twitter comments experiment

A couple of weeks ago I explored the idea of [using Twitter as the primary forum for blog discussion](http://dsandler.org/wp/archives/2009/02/26/twitter-comments). Multiple-round conversation is hard to sustain on a personal blog, but seems to appear effortlessly on Twitter, so went the thinking. Many people responded on Twitter (and elsewhere) with their thoughts, both on the general idea and the particular implementation; they were captured and displayed along with the original post using some client-side JavaScript called [watercooler.js](http://bitbucket.org/dsandler/watercooler) that I built for the experiment.
Below, I’ll share some of the points raised by those responses, along with some observations and data of my own.
### Discussion, I haz it
155 Twitter messages [matched](http://search.twitter.com/search?q=http%3A%2F%2Fdsandler.org%2Fwp%2Farchives%2F2009%2F02%2F26%2Ftwitter-comments+OR+d2nrsv) either the URL, TinyURL, or TinyURL path-component of the original post as of Friday the 6th of March, making it by far the most-discussed article ever on this site.  For comparison, the closest competitor (using conventional blog comments) is my 2006 [gripe about the iTunes 7 user interface](http://dsandler.org/wp/archives/2006/09/12/itunes-7-dissection), with 86 comments. Of those 86, 49 were actual comments (not trackbacks or pingbacks), of which 12 were mine. Five readers posted more than once—twice, in fact, in every case—and the remaining 43 comments were hand grenades (that is: fire and forget).
For comparison, the closest competitor (using conventional blog comments) is my 2006 [gripe about the iTunes 7 user interface](http://dsandler.org/wp/archives/2006/09/12/itunes-7-dissection), with 86 comments. Of those 86, 49 were actual comments (not trackbacks or pingbacks), of which 12 were mine. Five readers posted more than once—twice, in fact, in every case—and the remaining 43 comments were hand grenades (that is: fire and forget).
First: this is a tremendous level of interest for little old dsandler.org. I don’t have clear numbers about the readership of my blog—let’s put it at around 400[^RSS]—but it’s on the same order of magnitude as my Twitter subscribership.[^TWF] So we can say that the post had roughly the same audience on Twitter that it would have had otherwise, and yet, it received twice as many responses as the reigning champ on the blog.[^ETC]
[^ETC]: This isn’t apples-to-apples, of course: there are too many confounding factors here (RSS subscribership increase; selection bias of readers; size of excerpt seen by potential commenters) to consider the 2006 and 2009 posts as control and experiment. I’m merely pointing out, qualitatively, that this is the biggest response I’ve ever seen, by a factor of two. One environmental similarity between the two posts: they were each Fireballed ([2006](http://daringfireball.net/linked/2006/09/12/sandler), [2009](http://daringfireball.net/linked/2009/02/27/dsandler-comments)).
[^TWF]: Currently about [500 followers](http://twitter.com/dsandler/followers), which includes inactive accounts, spammers, and so on.
[^RSS]: Counting feed subscribers is known to be an inexact science (unless you [outsource](http://feedburner.com) all your feeds). Yesterday there were 2940 individual requests to the various WordPress feed URLs, so assuming the conventional half-hourly refresh rate, that’s a little over 60 individual fetchers; one of those is Google, which tells me in my logs that I have about 120 subscribers there; similarly, Bloglines adds another 60, Yahoo another 160. So, all told, I figure I’ve got around 400 readers out in RSS-land.
I believe that the ease of responding via Twitter, rather than
1. clicking through to the blog (if reading it via RSS)
2. finding the comments form
3. entering a bunch of orthogonal information (your email address, name, some
sort of anti-spam challenge)
before finally being able to enter a comment, was indeed conducive to discussion. Additionaly, Twitter facilitates the second hop (that is, reaching readers of my readers) thanks to the ease with which messages may be forwarded along (retweeted in the lingo).
### Digging into the data
One of the concerns raised by several commentators was that, while potentially valuable for increasing the reach of a blog post, these RTs would clog the discussion. Being an ABD [doctoral student in computer science](http://www.cs.rice.edu/~dsandler/), my conditioned response is to disprove this hypothesis with a graph:
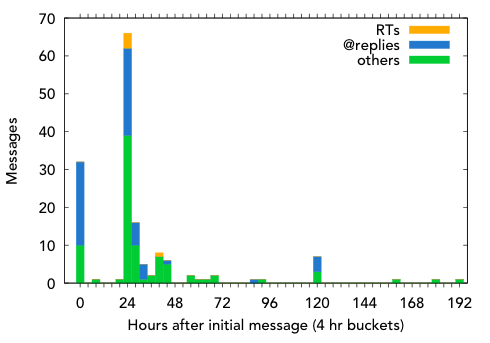
Fig. 1. Classification of Twitter replies over time.
See that big spike (Figure 1, at T+24 hours)? That’s when John Gruber [mentioned](http://daringfireball.net/linked/2009/02/27/dsandler-comments) the experiment on Daring Fireball, which proliferated the idea much more widely than my own immediate circle of attentive contacts (the spike at T=0). In fact, the orange retweet bar makes its first (and nearly only) appearance at T+24; in all, retweets made up only 3% (51 messages) of the weeklong discussion. @replies, a robust indicator of discussion rather than simply undirected opinion, represented 39% of the traffic.
So who was doing all this talking? Well, I was certainly responsible for a lot of it (more than a quarter), particularly at the beginning, where I was responding individually to responses from my friends. As mentions of the post broadened, there were fewer questions, so I had fewer responses (see Fig. 2).
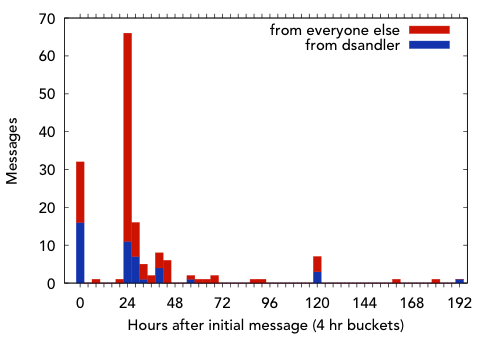
Fig. 2. Author (28%) vs. audience (72%).
Much of this was multiple-round discussion; 13 users had two tweets, several had 3, and some offered as many as 6 or 7 responses.
### Which way to the forum?
Beyond simply sparking conversation (easy enough to do with a single Twitter message), I wanted to be able to discover that conversation and *point* to it from the blog. It’s not a discussion if you can’t join in, and without a way to link all the relevant tweets together, there’s no way to collect them on the blog for easy perusal (which would be no better than having no comments facility at all).
In short, this technique needs a rendezvous point. The most obvious Twitter-compatible approach is to require respondents to embed in their messages a unique string that I could send to [search.twitter.com](http://search.twitter.com) to collect all the relevant messages at any time. I chose the TinyURL of the original post (later simplified to just the path part, [d2nrsv](http://preview.tinyurl.com/d2nrsv)) for two reasons:
1. Anyone making mention of the blog post in a Twitter message but oblivious to the conversation protocol would still have his message included in the conversation.
2. It’s unique across any site using the same technique.
So did I actually pick up any random messages (case #1 above)? Figure 3 tells the story:
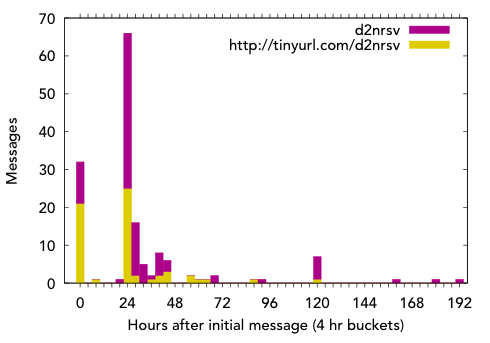
Fig. 3. TinyURL: fragments vs. full URLs.
Indeed, there were plenty of messages that included the full TinyURL. Those that did not either inferred the protocol from the messages of others, or used the “click here to comment??? link at the end of the blog post (which used the Twitter ?status= query string in order to pre-populate the input box with the “d2nrsv??? fragment, [like so](http://twitter.com/home?status=monkeys)).
Guessing what the “d2nrsv??? meant, however, wasn’t easy; in general, this approach suffers badly from a lack of self-documentation. It might have been better to satisfy goal #2 (globally unique) by generating a symbol of the form #dsandlerdotorg_twittercomments[^HashTag] that has some hope of being deciphered. A related approach might be to create a Twitter account for the blog and require discussion of the form “@dsandlerdotorg twittercomments Nice idea!???—a two-part hierarchical conversation identifier.[^AccountPer]
[^AccountPer]: Several people even proposed creating a whole new Twitter account for each post, such that @dsandlerdotorg_twittercomments would be both unique (enforced by Twitter) and fully scoped to the post. This seems like an abuse of Twitter, but a [more general micropublishing system](http://brdfdr.com) that allowed third parties to arbitrarily create new endpoints might be able to handle this easily. Worth coming back to.
[^HashTag]: Many suggested creating a unique hashtag, which has the benefit of being presented in many Twitter frontends as a quick search for that term. I’m mixed on this approach, mostly because I think hashtags are nerds-only tools that won’t really take hold as Twitter continues to grow past the early-adopter phase. #provemewrongfolks
It’s also worth noting that relying on TinyURL introduces fragility; such an external dependency can go down or change its behavior at any time, with huge impact to this technique. (Twitter has the same fate-sharing problem with TinyURL, which is why I’ve advocated for some time that Twitter needs to run its own URL-shortening service.)
Perhaps the best approach, as in so many situations, is to be liberal in what is accepted: search for (1) the TinyURL, (2) some sort-of-unique keyword referring to the post, possibly (3) directed as an @reply to a Twitter account for the blog. Maybe the unadorned @replies to the blog’s Twitter account (i.e., those without other identifying tokens) could be automatically associated with the latest prior post at that time. I’ll probably try something along these lines in my next revision of the watercooler code.
### Other important considerations
All this hassling over exactly which nonce to include in responses avoids the very real problem (again, pointed out by many) that to include a tag burns precious bytes, of which Twitter message text may only use 140. Of course, there’s plenty of metadata outside those 140 bytes that is nevertheless associated with each tweet (such as time, author, status ID of an antecedent message, and so forth), so we can imagine that an in_reply_to_url datum might not be an unreasonable addition to the overall structure. [^REPLY]
[^REPLY]: In fact, some proposed using the existing in_reply_to_status_id field to tie the conversation together, and indeed, this would be done automatically by many clients if I asked people to respond to a single tweet instead of including a token in their message text. Unfortunately, this wreaks havoc with messages that are in fact more directly tied to some other message—particularly a more recent tweet in the thread. I think that both pointers, ultimately, are required: one for the *conversation* to which a message belongs, and one for the *messages* (not necessarily just one) to which a message is a direct response.
A number of people mentioned that sharing fate with Twitter search is also potentially problematic. It might not survive as long as your blog, or its API might change (forcing you to upgrade your blog to recover the comments), or it might start returning inconsistent or undesirable data (for example, [truncating result sets during peak load](http://twitter.com/AlexSchleber/status/1275367958)). More generally, there was a general sense (with which I agree) that while Twitter might be a really interesting way to discuss something, if you want to collect that discussion in one place, you really ought to be copying it there. This has the unfortunate side-effect of obviating the cleverness of the [watercooler.js implementation](http://bitbucket.org/dsandler/watercooler), which is entirely client-side and therefore puts plenty of load on Twitter but none on the original author’s blog. A future implementation should create a permanent local copy of all relevant public tweets, so that they persist as long as the antecedent article does.[^COPY]
[^COPY]: I did this by hand on March 5, copying the generated HTML into the end of my [original post](http://dsandler.org/wp/archives/2009/02/26/twitter-comments), and in so doing I truncated the “official??? record of the discussion at that time.
### Once more unto the data, my friends
Finally, if you’d like to see what you can make of all this, I’ll save you the trouble of fetching the data from the Twitter Search API: [here is JSON](/entries/images/2009/watercooler/all.json) for the tweets used to produce the graphs above. If you see any interesting trends in there that I didn’t catch, please share it with the class; as before, include in your message the [TinyURL path, dc946u](http://twitter.com/home?status=[re:dc946u]+) or full URL.